LDA的生成过程
LDA是一个生成式概率模型描述数据如何被生成的概率模型,可以用于生成新的数据样本,它描述了文档集合的生成过程。理解这个过程对掌握LDA的核心原理至关重要。

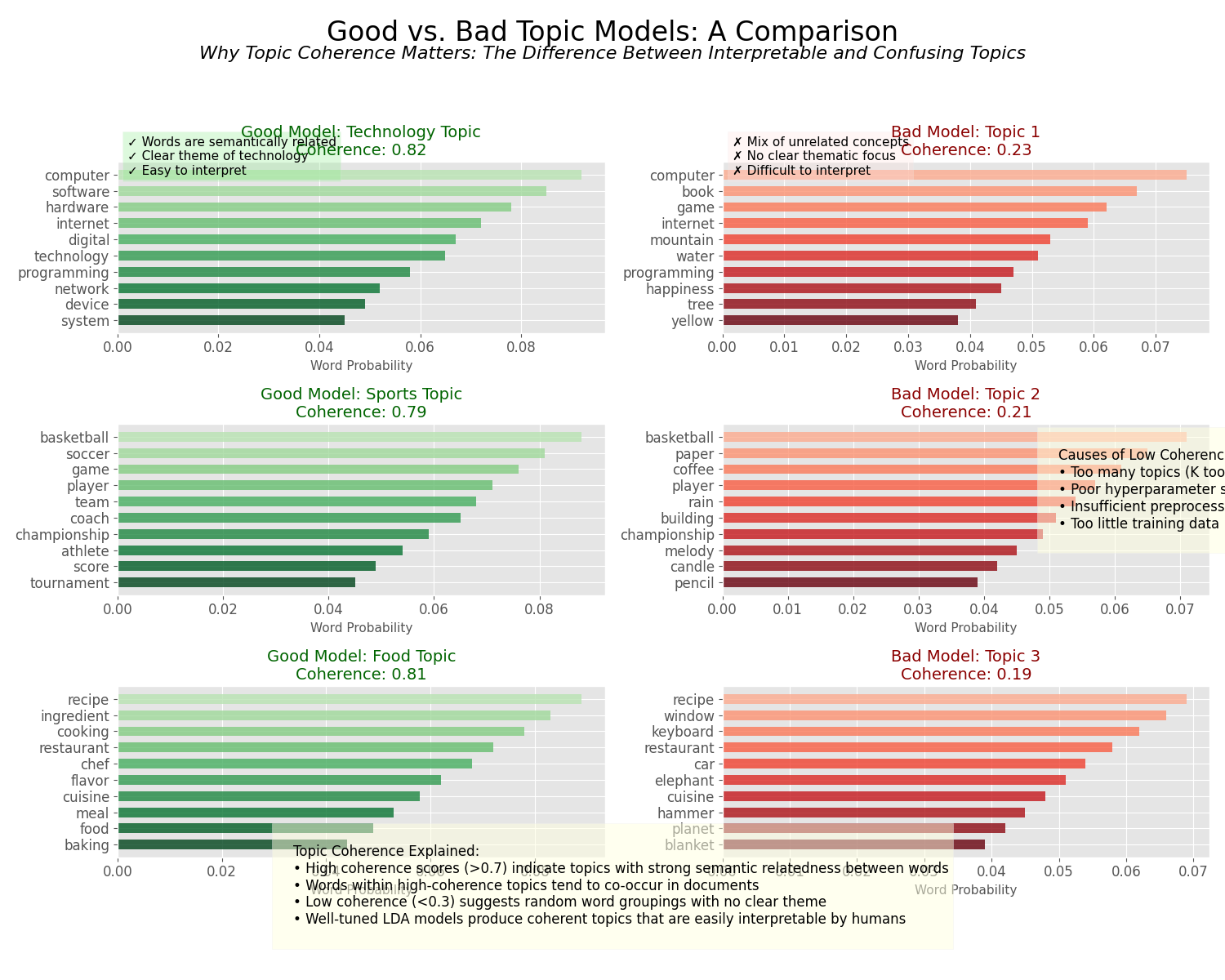
图1:LDA生成过程的可视化解释,展示了从主题分布到词语生成的全过程
LDA生成过程的步骤解析
步骤1:为语料库选择主题数量K
首先,研究者需要指定模型中主题的数量K。这是一个需要根据数据特性和分析需求来确定的超参数。
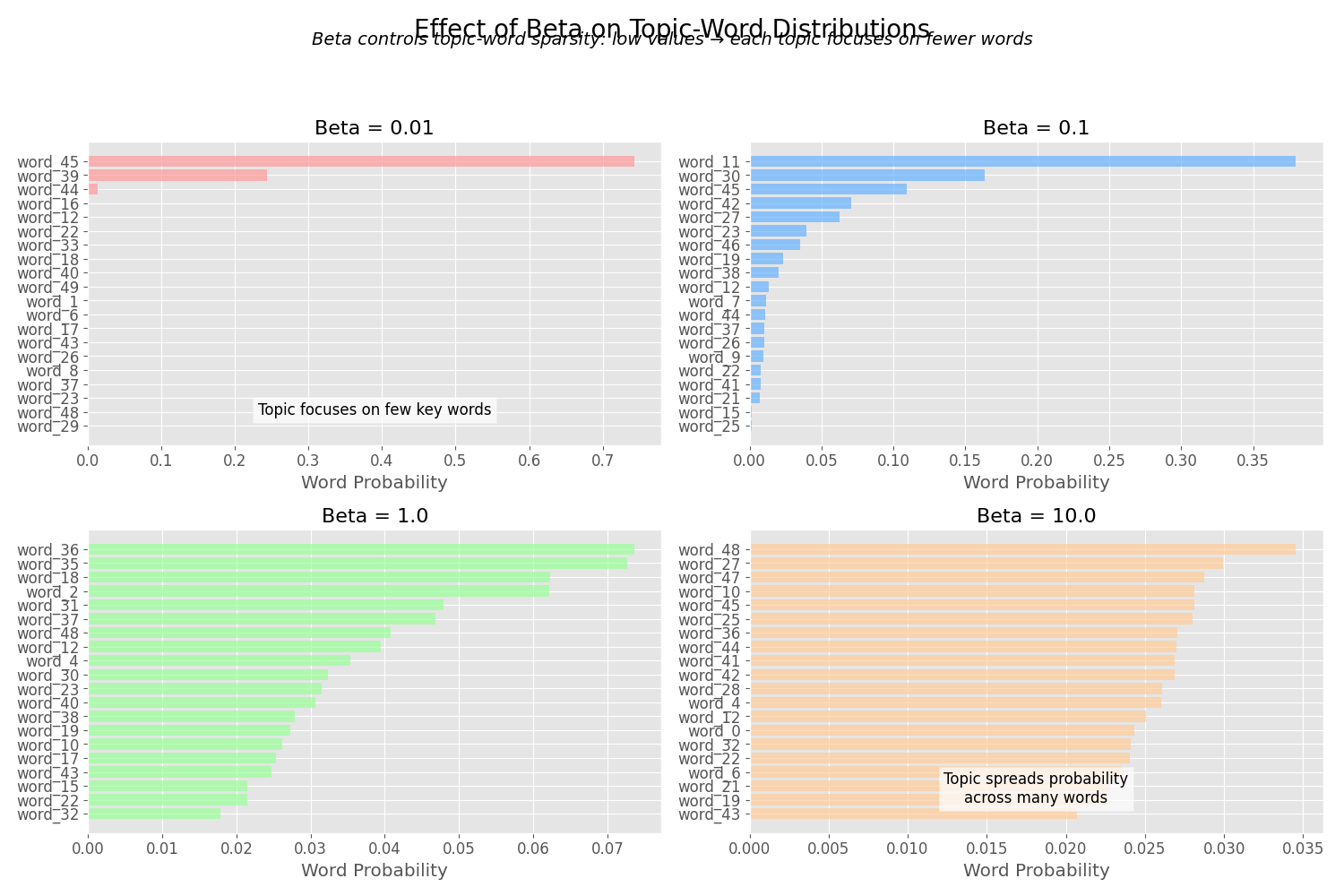
步骤2:为每个主题生成词语分布
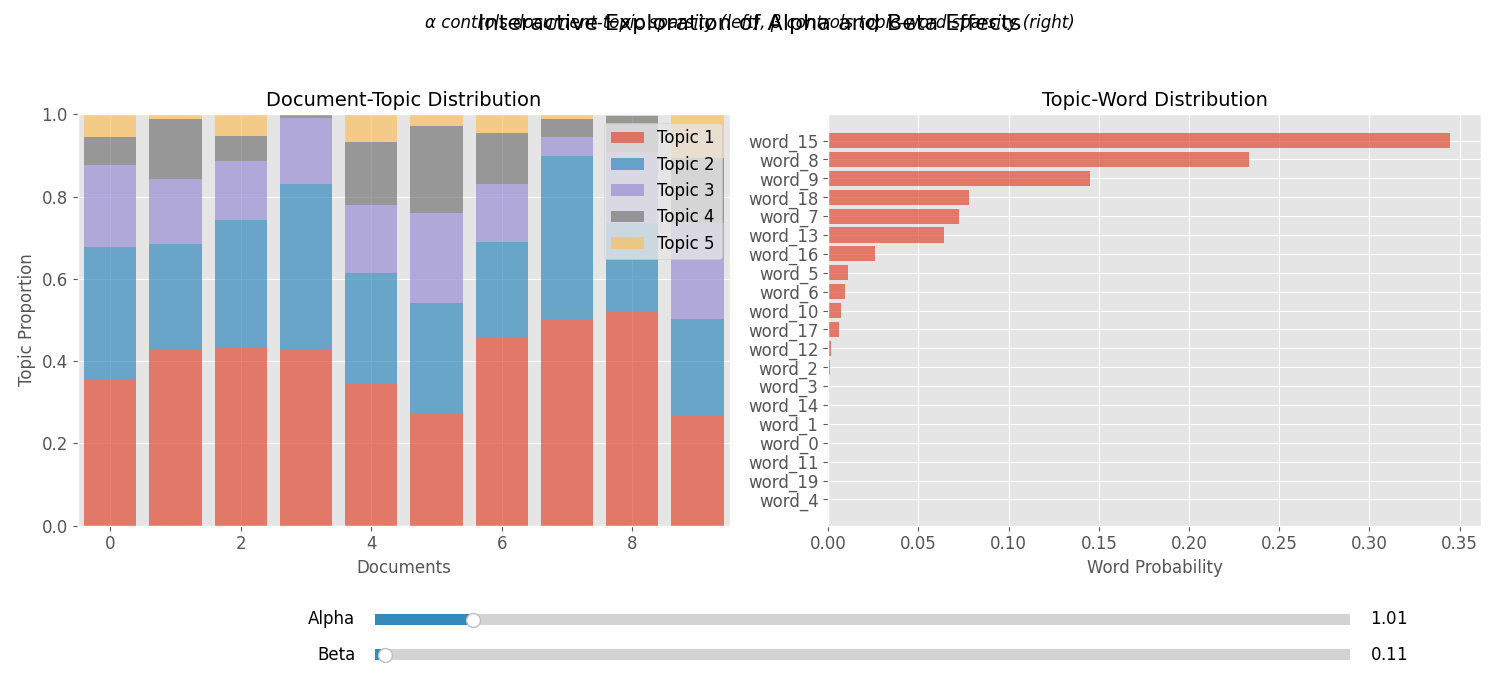
对于每个主题k,从狄利克雷分布Dir(β)中抽取一个词语分布φk。这个分布决定了特定主题下不同词语出现的概率。
其中β是控制主题词分布形状的超参数,我们稍后会详细讨论。
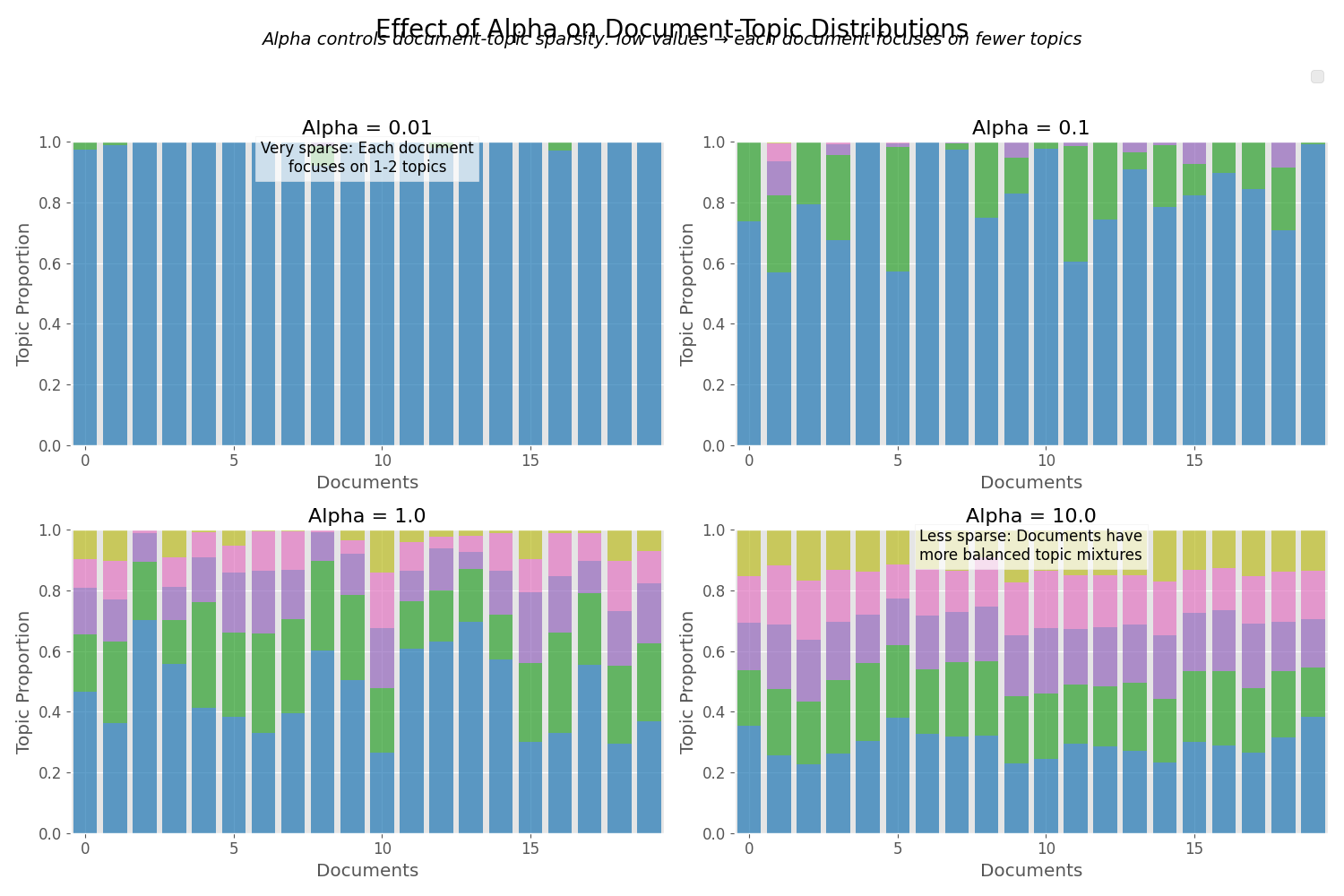
步骤3:为每篇文档生成主题分布
对于每篇文档d,从狄利克雷分布Dir(α)中抽取一个主题分布θd。这个分布决定了特定文档中不同主题出现的比例。
其中α是控制文档主题分布形状的超参数,我们稍后会详细讨论。
步骤4:为每篇文档中的每个词生成主题和词语
对于文档d中的每个位置i:
- 从文档的主题分布θd中抽取一个主题zd,i
- 从主题zd,i对应的词语分布φzd,i中抽取一个词语wd,i
生成过程例子:电影评论
假设我们有3个主题:"情节"、"视觉效果"和"表演"。
每个主题有各自的词语分布:
- "情节"主题:{故事:0.3, 剧情:0.25, 节奏:0.15, 结构:0.1...}
- "视觉效果"主题:{特效:0.35, 画面:0.2, 场景:0.15, 视觉:0.1...}
- "表演"主题:{演员:0.3, 角色:0.25, 表演:0.2, 演技:0.15...}
现在生成一篇关于《复仇者联盟》的评论:
- 为这篇评论生成主题分布:{"情节":0.2, "视觉效果":0.5, "表演":0.3}
- 对于评论中的每个词位置:
- 按主题分布抽取一个主题(如"视觉效果")
- 从该主题的词语分布中抽取一个词(如"特效")
重复上述过程,我们可能生成:"特效非常震撼,演员表现出色,画面精美,情节紧凑..."
LDA的核心任务是从已观察到的文档集合中,推断出每个主题的词语分布和每篇文档的主题分布。这是一个逆向工程根据观察到的结果(文档中的词语)推断生成这些结果的隐藏变量(主题分布和词语分布)的过程。